Data Warehouse vs Data Mart vs Data Lake
The terms data lake and data warehouse are often confused and sometimes used interchangeably. In fact, while both are used to store massive datasets, data lakes and data warehouses are different (and can be complementary).
- Data Lake - is a massive pool of data that can contain any type of data—structured, semi-structured or unstructured.
- Data warehouse - is a repository for structured, filtered data that has already been processed for a specific purpose. In other words, a data warehouse is well-organized and contains well-defined data.
- Data mart - is a subset of a data warehouse, used by a specific enterprise business unit for a specific purpose such as a supply chain management application.
James Dixon, the originator of the data lake term, explains the differences by way of analogy: “If you think of a data mart as a store of bottled water - cleansed and packaged and structured for easy consumption - the data lake is a large body of water in a more natural state. The contents of the data lake stream in from a source to fill the lake, and various users of the lake can come to examine, dive in, or take samples.”
A data lake can be used in conjunction with a data warehouse. For example, you can use a data lake as a landing and staging repository for a data warehouse. You can use the data lake to curate or cleanse data before feeding it into a data warehouse or other data structures.
Data lakes that are not curated run the risk of becoming data swamps with no governance or quality decisions applied to the data, radically decreasing the value of collecting the data by “muddying” mixed quality data together in a way that makes it difficult to rely on the validity of decisions being made from the collected data.
The following diagram represents a typical data lake technology stack. The data lake includes scalable storage and compute resources; data processing tools for managing data; analytics and reporting tools for data scientists, business users and technical personnel; and common data governance, security and operations systems.
You can implement a data lake in an enterprise data center or in the cloud. Many early adopters deployed data lakes on-premises. As data lakes become more prevalent, many mainstream adopters are looking to cloud-based data lakes to accelerate time-to-value, reduce TCO and improve business agility.
On-Premises Data Lakes are CAPEX and OPEX Intensive
You can implement a data lake in an enterprise data center using commodity servers and local (internal) storage. Today most on-premises data lakes use a commercial or open-source version of Hadoop, a popular high-performance computing framework, as a data platform. (In the TDWI survey, 53% of respondents are using Hadoop as their data platform, while only 6% are using a relational database management system.)
You can combine hundreds or thousands of servers to create a scalable and resilient Hadoop cluster, capable of storing and processing massive datasets. The diagram below depicts a technology stack for an on-premises data lake on Apache Hadoop.
The technology stack includes:
-
Hadoop MapReduce:
A software framework for easily writing applications that process vast amounts of data in-parallel on large clusters of commodity hardware in a reliable, fault-tolerant manner.
-
Hadoop YARN:
A framework for job scheduling and cluster resource management.
-
Hadoop Distributed File System (HDFS):
A high-performance file system specifically designed to run on low-cost servers, with inexpensive internal disk drives.
On-premises data lakes provide high performance and strong security, but they are notoriously expensive and complicated to deploy, administer, maintain and scale. Disadvantages of an on-premises data lake include:
Long-drawn-out installation
Building your own data lake takes significant time, effort and money. You have to design and architect the system; define and institute security and administrative systems and best practices; procure, stand up and test the compute, storage and networking infrastructure; and identify, install and configure all the software components. It usually takes months (often over a year) to get an on-prem data lake up and running in production.
High CAPEX
Substantial upfront equipment outlays lead to lopsided business models with poor ROIs and long paybacks. Servers, disks and network infrastructure are all over-engineered to meet peak traffic demands and future capacity requirements, so you are always paying for idle compute resources and unused storage and network capacity.
High OPEX
Recurring power, cooling and rack space expenses; monthly hardware maintenance and software support fees; and ongoing hardware administration costs all lead to high equipment operations expenses.
High risk
Ensuring business continuity (replicating live data to a secondary data center) is an expensive proposition beyond the reach of most enterprises. Many enterprises back up data to tape or disk. In the event of a catastrophe it can take days or even weeks to rebuild systems and restore operations.
Complex system administration
Running an on-premises data lake is a resource-intensive proposition that diverts valuable (and expensive) IT personnel from more strategic endeavors.
Cloud Data Lakes Eliminate Equipment Cost and Complexity
You can implement a data lake in a public cloud to avoid equipment expenses and hassles and accelerate big data initiatives. The general advantages of a cloud-based data lake include:
Rapid time-to-value
You can slash rollout times from months to weeks by eliminating infrastructure design efforts and hardware procurement, installation and turn-up tasks.
No CAPEX
You can avoid upfront capital outlays, better align expenses with business requirements and free up capital budget for other programs.
No equipment operating expenses
You can eliminate ongoing equipment operations expenses (power, cooling, real estate), annual hardware maintenance fees and recurring system administration costs.
Instant and infinite scalability
You can add compute and storage capacity on-demand to meet rapidly evolving business requirements and improve customer satisfaction (respond quickly to line-of-business requirements).
Independent scaling
Unlike with an on-premises Hadoop implementation that relies on servers with internal storage, with a cloud implementation you can scale compute and storage capacity independently to optimize costs and make maximum use of resources.
Lower risk
You can replicate data across regions to improve resiliency and ensure continuous availability in the event of a catastrophe.
Simplified operations
You can free up IT staff to focus on strategic tasks to support the business (the cloud provider manages the physical infrastructure).
First-Gen Cloud Storage Services are too Costly and Complex for Data Lakes
Compared to an on-premises data lake, a cloud-based data lake is far easier and less expensive to deploy, scale and operate. That said, first-generation cloud object storage services like AWS S3, Microsoft Azure Blob Storage and Google Cloud Platform Storage are inherently costly (in many cases being just as expensive as on-premises storage solutions) and complicated. Many enterprises are seeking simpler, more affordable storage services for data lake initiatives. Limitations of first-generation cloud object storage services include:
Expensive and confusing service tiers
Legacy cloud vendors sell several different types (tiers) of storage services. Each tier is intended for a distinct purpose e.g. primary storage for active data, active archival storage for disaster recovery, or inactive archival storage for long-term data retention. Each has unique performance and resiliency characteristics, SLAs and pricing schedules. Complicated fee structures with multiple pricing variables make it difficult to make educated choices, forecast costs and manage budgets.
Vendor lock-in
Each service provider supports a unique API. Switching services is an expensive and time-consuming proposition—you have to rewrite or swap out your existing storage management tools and apps. Worse still, legacy vendors charge excessive data transfer (egress) fees to move data out of their clouds, making it expensive to switch providers or leverage a mix of providers.
Beware of Tiered Storage Services
First-generation cloud storage providers offer confusing tiered storage services. Each storage tier is intended for a specific type of data, and has distinct performance characteristics, SLAs and pricing plans (with complex fee structures).
While each vendor's portfolio is slightly different, these tiered services are generally optimized for three distinct classes of data.
Active Data
Live data that is readily accessible by the operating system, an application or users. Active data is frequently accessed and has stringent read/write performance requirements.
Active Archive
Occasionally accessed data that is available instantly online (not restored and rehydrated from an offline or remote source). Examples include backup data for rapid disaster recovery or large video files that might be accessed from time-to-time on short notice.
Inactive Archive
Infrequently accessed data. Examples include data maintained long-term for regulatory compliance. Historically, inactive data is archived to tape and stored offsite.
Identifying the best storage class (and best value) for a particular application can be a real challenge with a legacy cloud storage provider. Microsoft Azure, for example, offers four distinct object storage options: General Purpose v1, General Purpose v2, Blob Storage and Premium Blob Storage. Each option has unique pricing and performance characteristics. And some (but not all) of the options support three distinct storage tiers, with distinct SLAs and fees: hot storage (for frequently accessed data), cool storage (for infrequently accessed data) and archive storage (for rarely accessed data). With so many choices and pricing variables, it is nearly impossible to make a well-informed decision and to accurately budget expenses.
At IDrive® e2, we believe cloud storage should be simple. Unlike legacy cloud storage services with confusing storage tiers and convoluted pricing schemes, we provide a single product—with predictable, affordable and straightforward pricing—that satisfies any cloud storage requirement. You can use IDrive® e2 for any data storage class: active data, active archive and inactive archive.
IDrive® e2 Hot Cloud Storage for Data Lakes
IDrive® e2 hot cloud storage is extremely economical, fast and reliable cloud object storage for any purpose. Unlike first-generation cloud storage services with confusing storage tiers and complex pricing schemes, IDrive® e2 is easy to understand and extremely cost-effective to scale. IDrive® e2 is ideal for storing massive volumes of raw data.
IDrive® e2's key advantages for data lakes include:
Commodity pricing
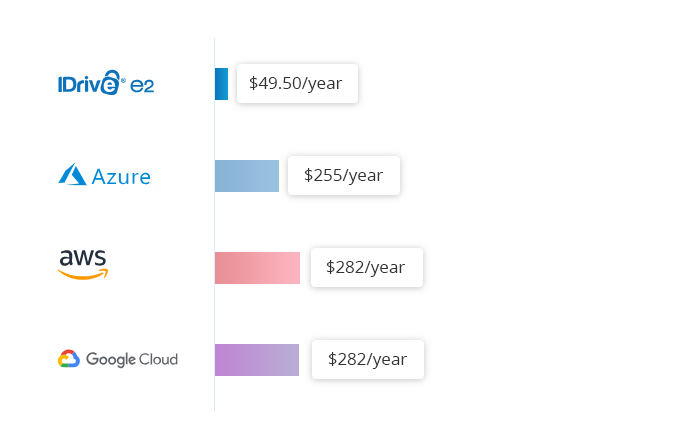
IDrive® e2 hot cloud storage costs a flat $0.004/GB/month. Compare that to $.023/GB/month for Amazon S3 Standard, $.026/GB/month for Google Multi-Regional and $.046/GB/month for Azure RA-GRS Hot.
Unlike AWS, Microsoft Azure and Google Cloud Platform we do not impose extra fees to retrieve data from storage (egress fees). We also do not charge extra fees for API calls.
Superior performance
IDrive® e2's parallelized system architecture delivers faster read/write performances than first-generation cloud-storage services, with significantly faster time-to-first-byte speeds.
Robust data durability and protection
IDrive® e2 hot cloud storage is built to deliver extreme data durability, integrity and security. An optional data immutability capability prevents accidental deletions and administrative mishaps; protects against malware, bugs and viruses; and improves regulatory compliance.
IDrive® e2 Hot Cloud Storage for Apache Hadoop Data Lakes
If you run your data lake on Apache Hadoop, you can use IDrive® e2 hot cloud storage as an affordable alternative to HDFS, as shown in the diagram below. IDrive® e2 hot cloud storage is fully compatible with the AWS S3 API. You can use the Hadoop Amazon S3A connector, part of the open-source Apache Hadoop distribution, to integrate Amazon S3 and other compatible cloud storage like IDrive® e2 into various MapReduce flows.
You can use IDrive® e2 hot cloud storage as part of a multi-cloud data lake implementation to improve choice and avoid vendor lock-in. A multi-cloud approach lets you scale data lake compute and storage resources independently, using best-of-breed providers.
You can also connect your private cloud directly to IDrive® e2. Unlike with first-generation cloud storage providers, with IDrive® e2 you never pay data transfer (egress) fees. In other words, you can freely move data out of IDrive® e2.
Economical Business Continuity and Disaster Recovery
IDrive® e2 is hosted in multiple, geographically distributed data centers for resiliency and high availability. You can replicate data across IDrive® e2 regions for business continuity, disaster recovery and data protection, as shown below.
For example, you could replicate data across three different IDrive® e2 data centers (regions) using:
- IDrive® e2 Data Center 1 for active data storage (primary storage).
- IDrive® e2 Data Center 2 as an active archive for backup and recovery (hot standby in the event Data Center 1 is unreachable).
- IDrive® e2 Data Center 3 as an immutable data store (to protect data against administrative mishaps, accidental deletions and ransomware). An immutable data object cannot be deleted or modified by anyone, including IDrive® e2.